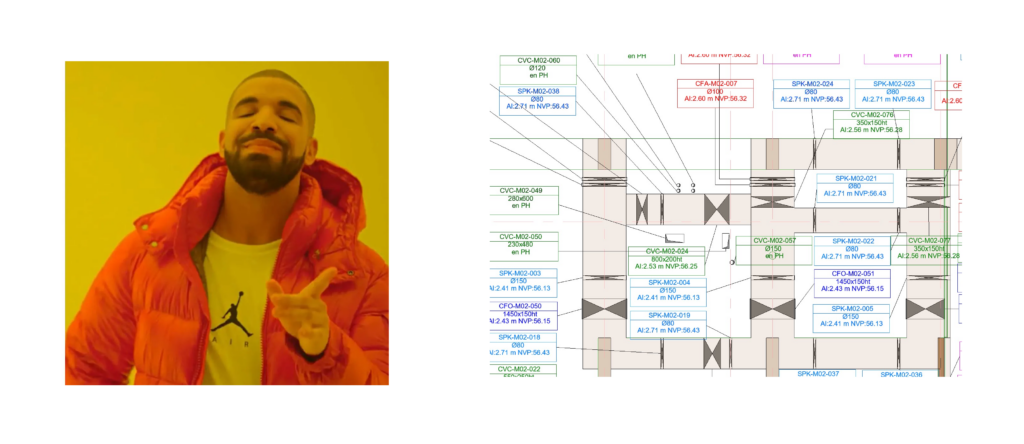
Plans made clearer
in few seconds.
• Well-organized plans make the right information stand out.
• Enhance readability with structured, appealing drawings at one click.
• Introducing Beautiful Docs, your AI-powered Add-in for Autodesk Revit.
Get notified when it’s ready
Join the waiting list to get updates on project progress and be notified when the add-in is available.
Behind the Build : The Development Notes
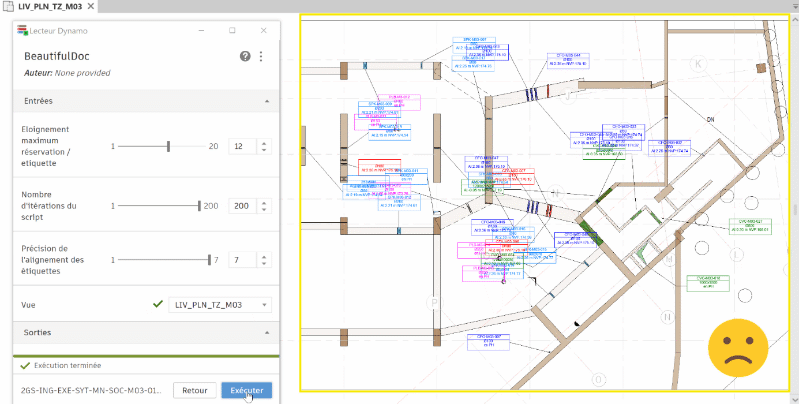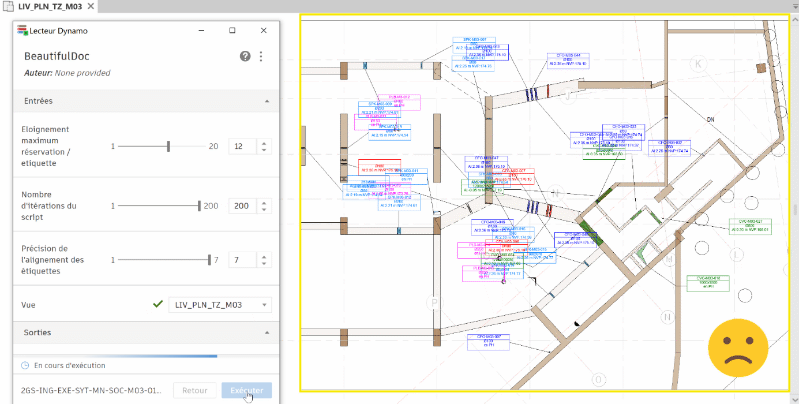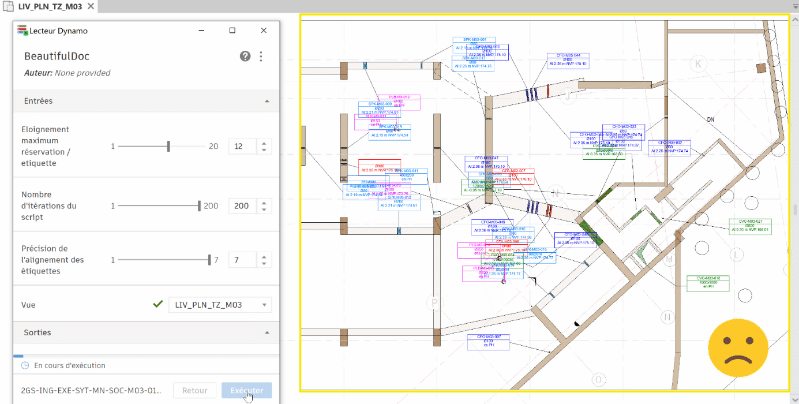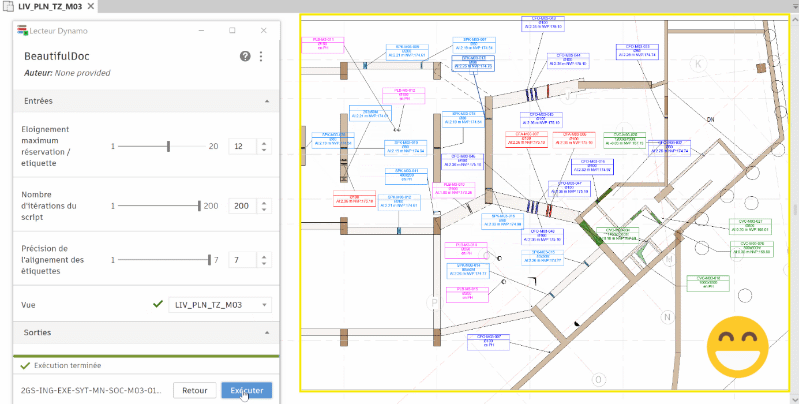
You shall not overlap !
24-09-2024
I recently expanded my Convolutional Neural Network model’s training dataset to 245 examples of disorganized and organized plan tags. However, the expected improvements in prediction accuracy haven’t materialized as significantly as I’d hoped.
This prompted me to revisit the model’s configuration, as outlined in my previous article. After refining the convolutional layer’s stride parameter, the model began making more relevant relationships during training. As a result, predictions have become more accurate, particularly in reducing tag overlap and positioning tags closer to their corresponding openings.
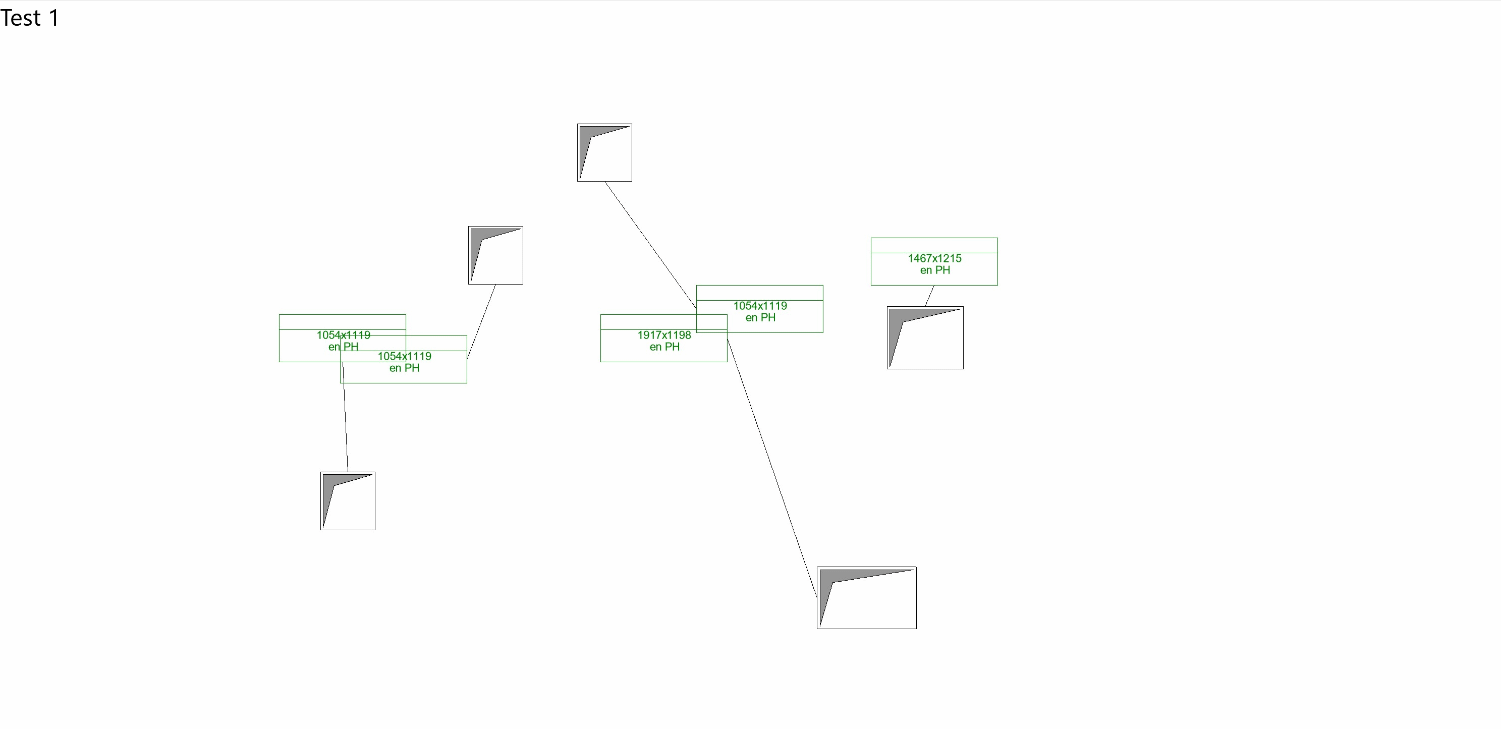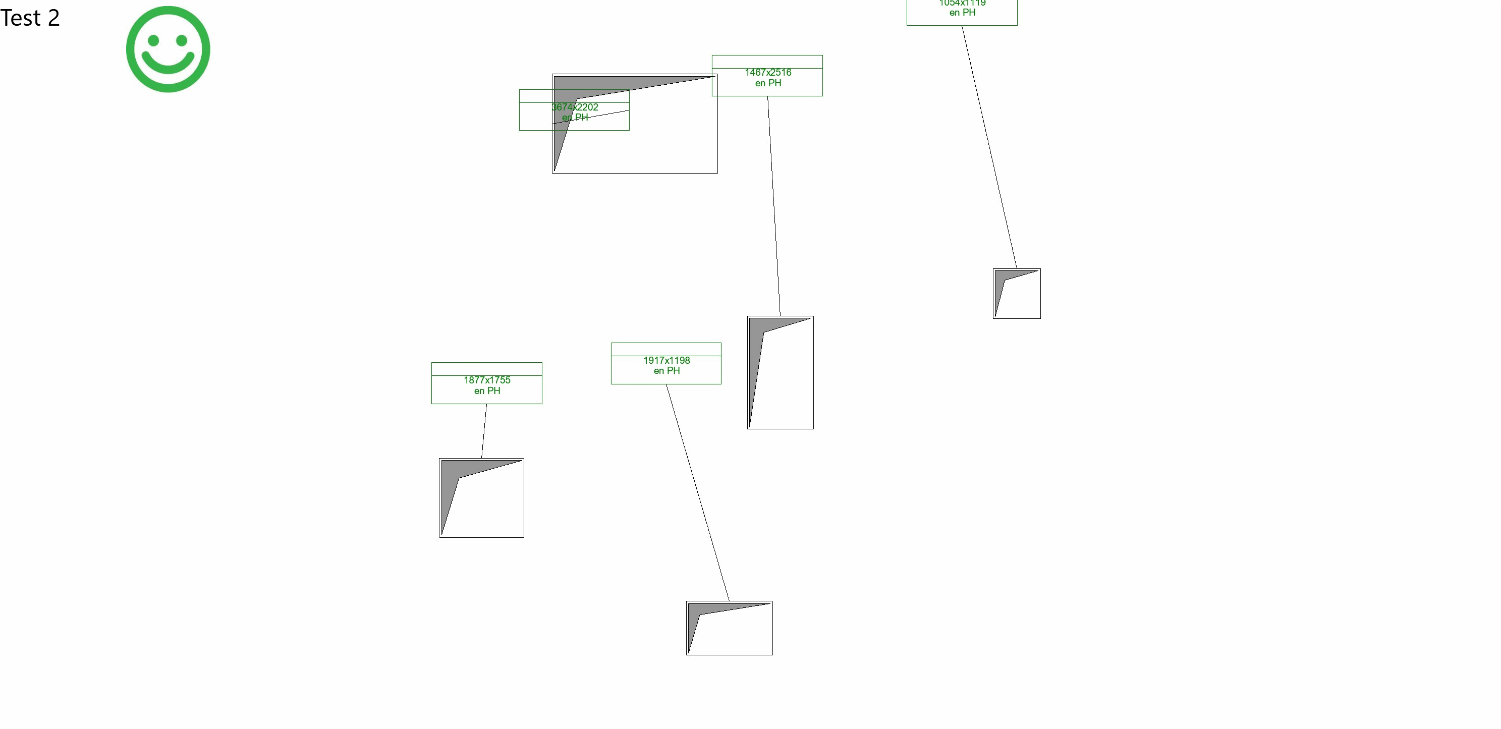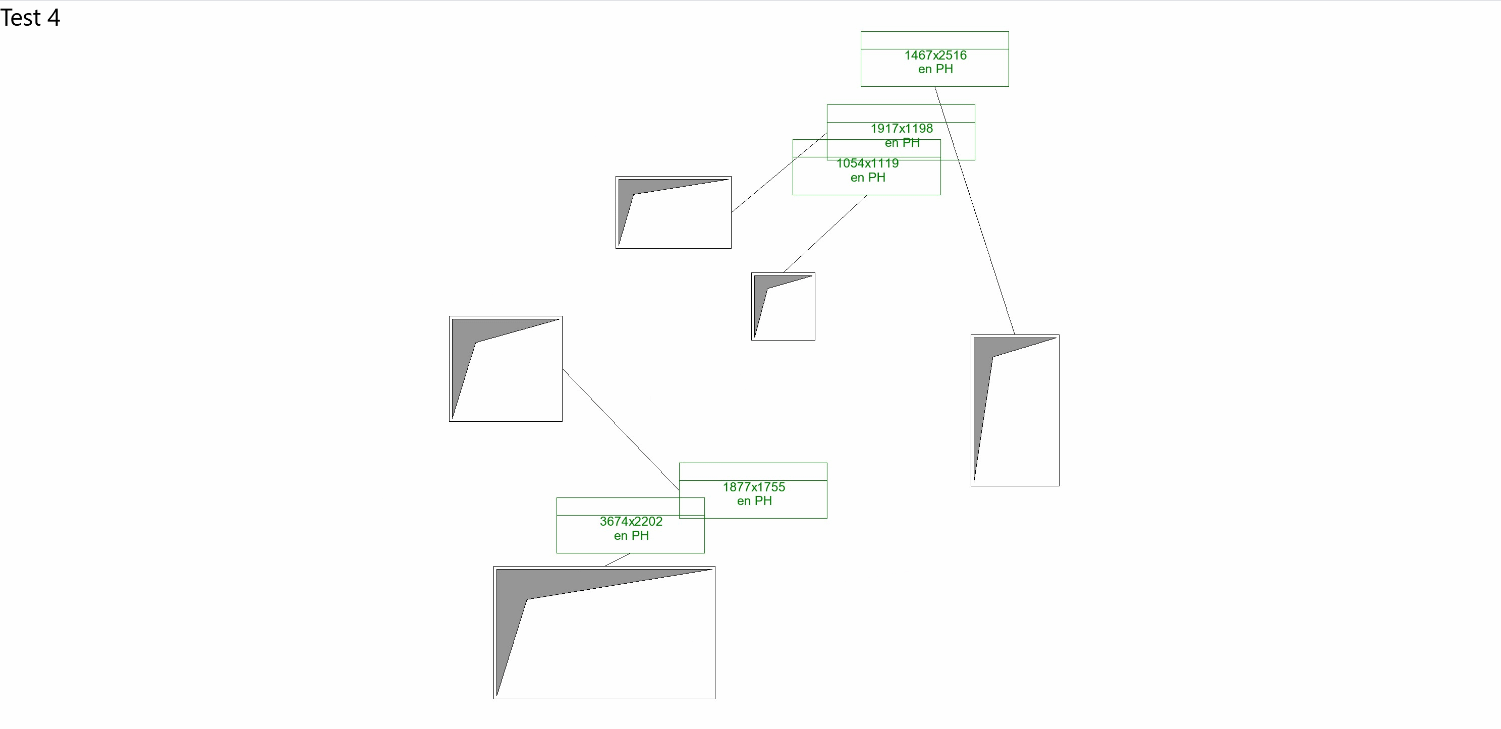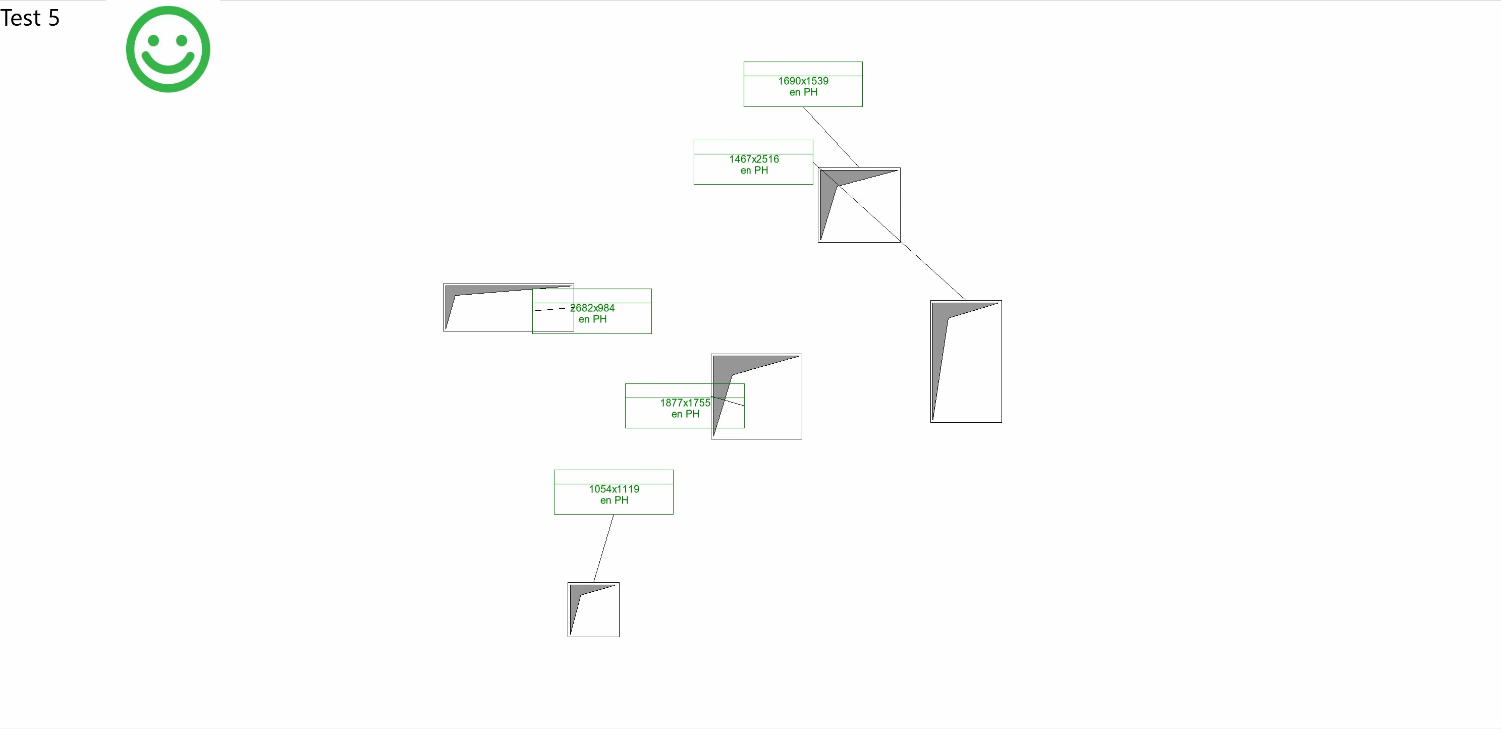
That said, the improvements are less apparent when dealing with linear patterns (e.g., walls) or rectangular structures (e.g., service shafts).
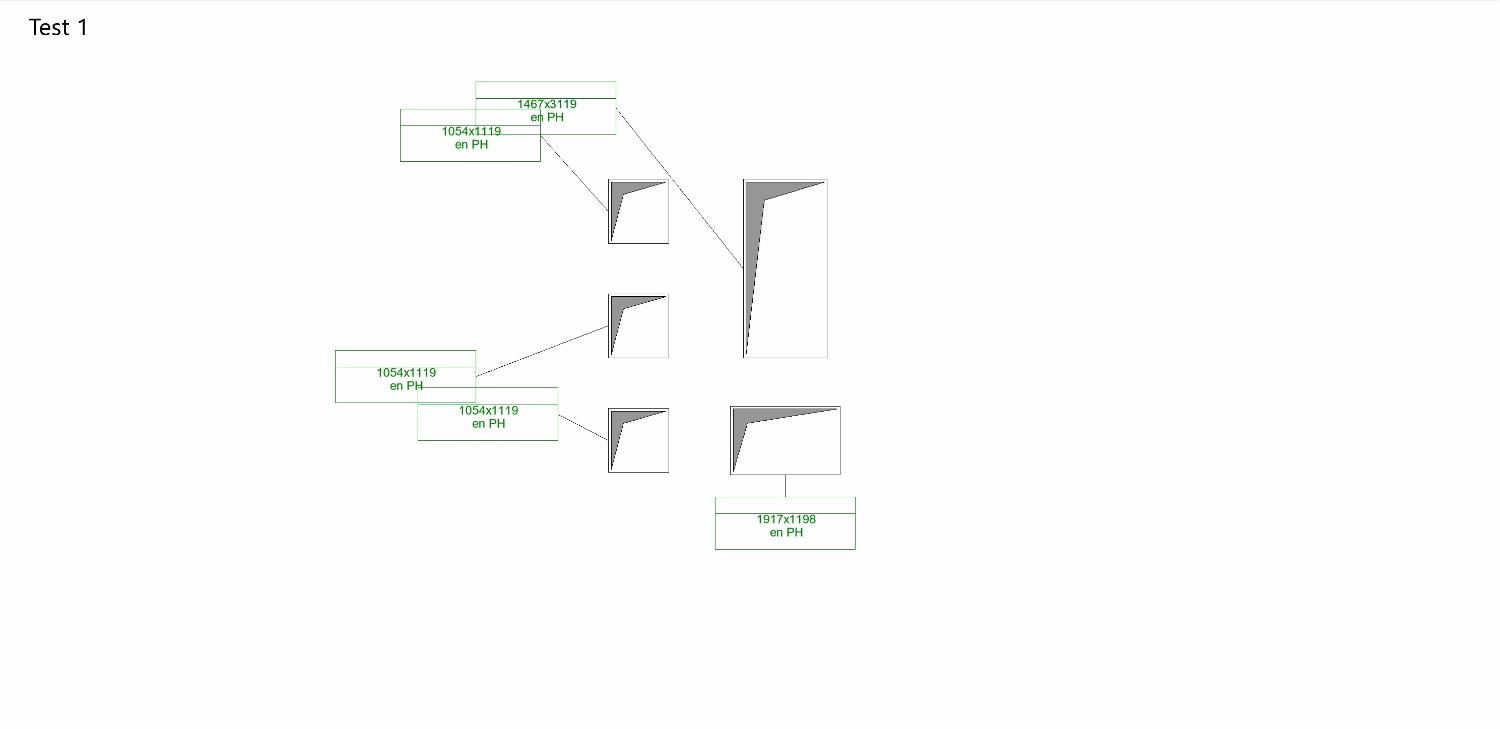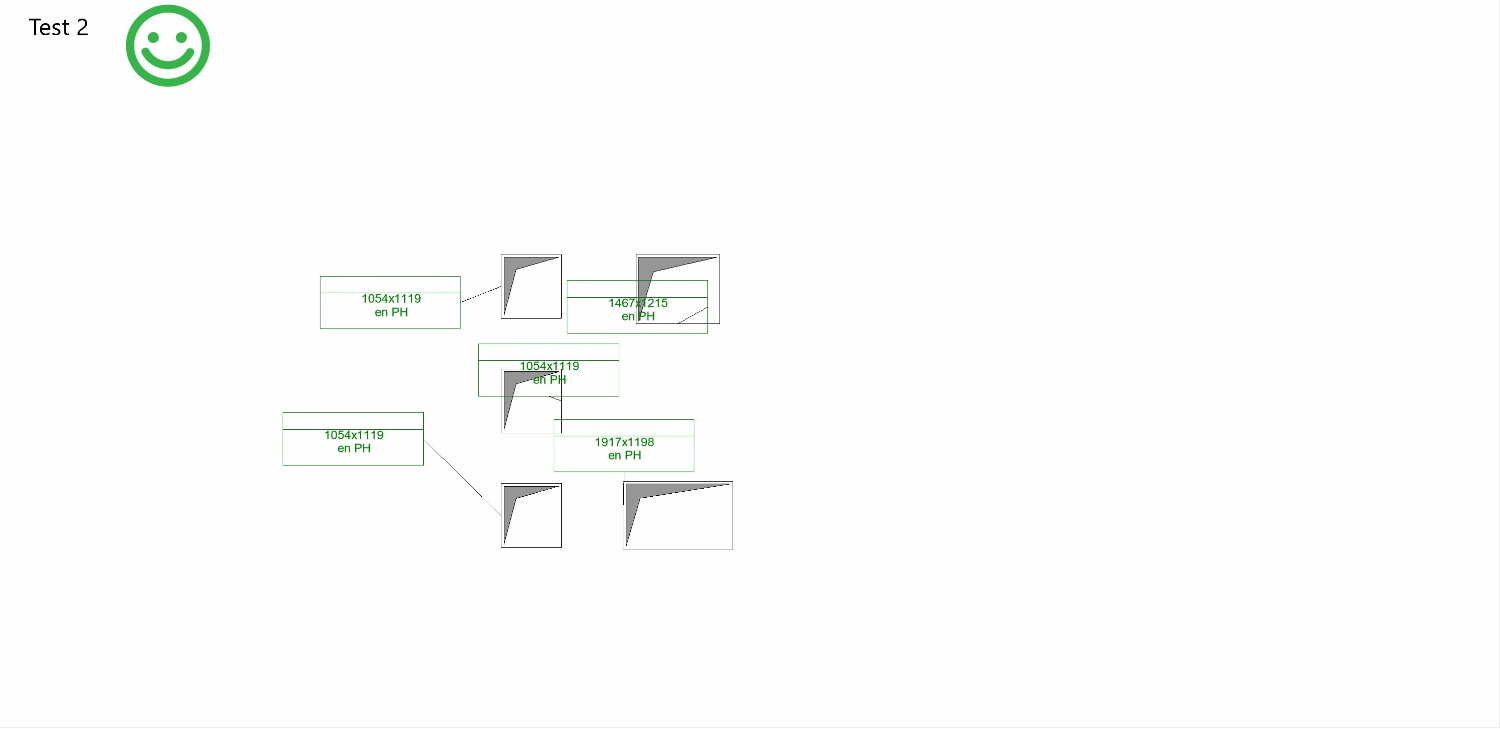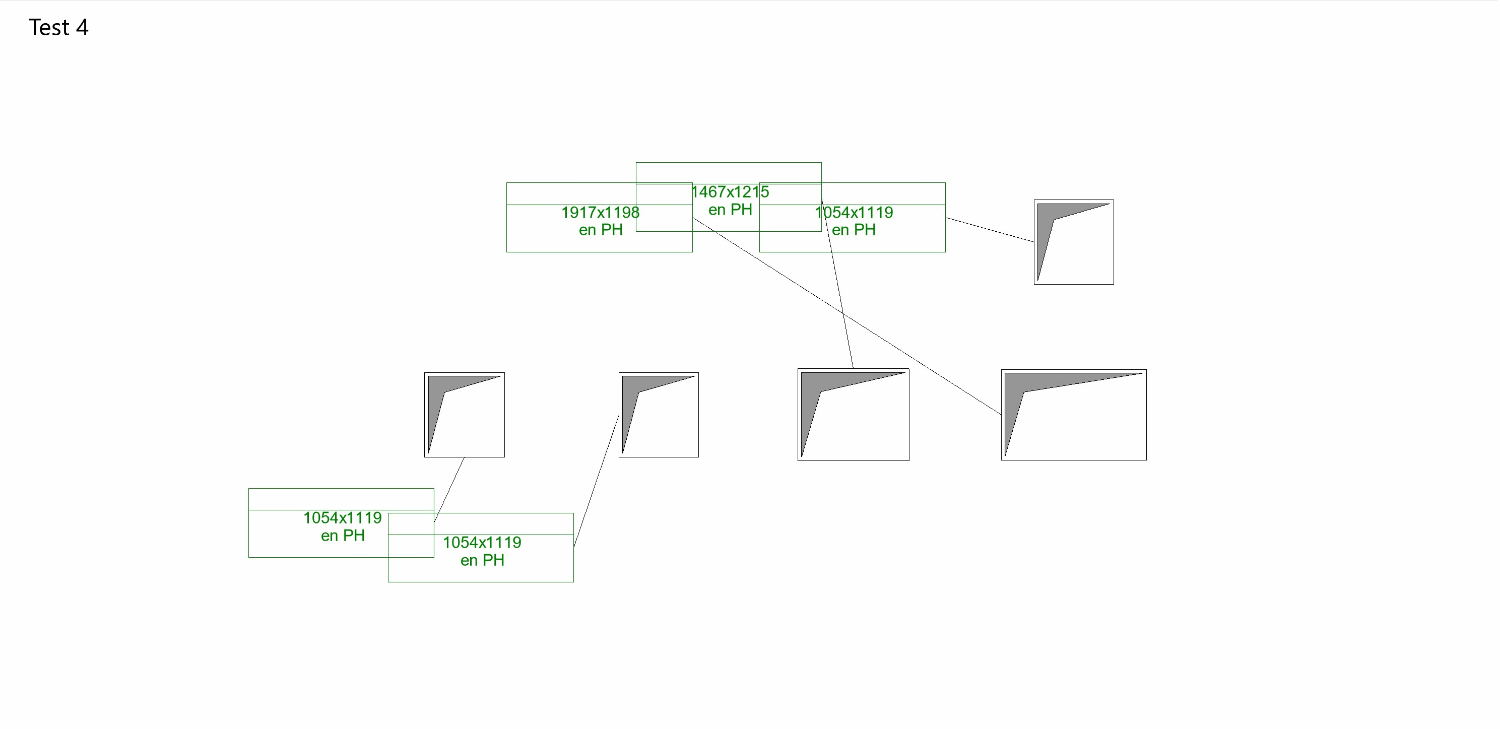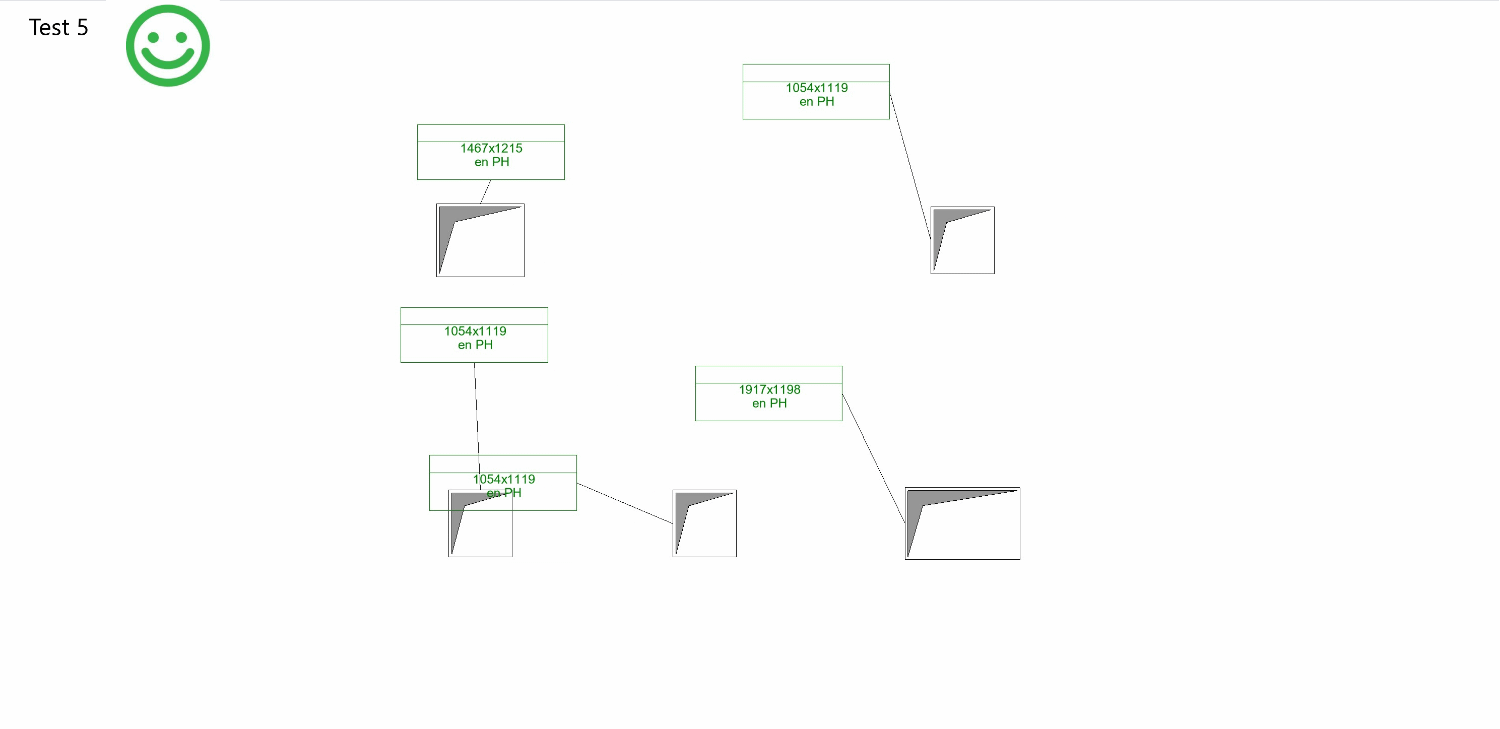
Overall, my goals for improvement remain:
- Eliminating tag overlap
- Avoiding overlap between tags and openings
- Positioning tags to reflect the pattern of their related openings
At this point, I need to balance adding more before-and-after examples of openings and adjusting the model’s parameters.
To be continued 😉
Improving the Accuracy of My CNN Model:
A Structured Approach
21-09-2024
I recently added more datasets to train my CNN model, aiming to improve its accuracy. However, the results haven’t shown significant improvement. This led me to reconsider how I configure the model and the factors affecting its performance.
In deep learning, a model’s accuracy depends on three key factors:
- Training configuration: How the model is set up.
- Data structure: How the training data is organized.
- Data volume: The amount of data available for training.
Since increasing the amount of data didn’t lead to better results, I started questioning whether the 250 input/output examples I had were sufficient or if I needed to adjust the model’s training parameters.
I decided to explore the latter by fine-tuning the training parameters. To make the necessary adjustments, I first sought to better understand how to configure the training of my CNN model.
A CNN model is composed of of layers. A layer is set of structured computational functions, each serving a specific purpose and helping the model learn and extract features from the input data. A CNN model has three main types of layers :
- Convolutional Layer
- Pooling Layer
- Fully Connected Layer
Given my focus on improving accuracy, I concentrated on the convolutional layer, which is crucial in identifying patterns in the data.
The Role of the Convolutional Layer
Convolution in a CNN is about detecting small, localized patterns within the data. For example, I want my model to detect alignment and overlap patterns between a tag and its associated element.
For this purpose, I described each tag/element pair in my dataset by several properties:
- Tag: Central point (X, Y), width, height
- Tagged Element: Central point (X, Y), width, height
More specifically, I structured these properties as the following sequence :
[Tag central point X coordinate, Tag central point Y coordinate, Tag Width, Tag height, Tagged element central point X coordinate, Tagged element central point Y coordinate,Tagged element width, Tagged element height]
Since these properties are organized in a sequential manner , a one-dimensional convolutional layer is used to process the data. The convolutional layer analyzes this input using a kernel, a function that acts as a sliding window, moving over the input sequence to capture relationships between adjacent values.
Initially, my model compared two values at a time, but it didn’t always compare the most relevant ones. For example, it compared:
- Tag central point X and Y coordinates (position pattern : relevant )
- Tag Y coordinate and width (not relevant)
- Tag width and height (surface-related pattern : relevant)
While the first and third comparisons were meaningful, the second comparison introduced irrelevant patterns. As a result, the model was being trained on non-relevant information, which likely caused inaccuracies in its predictions.
The Importance of the Stride Parameter
The key to solving this issue lay in adjusting the stride parameter in the convolutional layer. The stride is a setting that controls the step size for comparing values in the input sequence.
By using a stride value of two, the model now compares more relevant data points, such as:
- Tag central point X and Y coordinates (position : relevant)
- Tag width and height (surface : relevant)
- Tagged element central point X and Y coordinates (position : relevant)
- Tagged element width and height (surface : relevant)
These comparisons are more meaningful and help the CNN model focus on the correct patterns in both the input and output sequences. As a result, the model’s logic for making predictions becomes more accurate.
Getting started
14-09-2024
I’m developing an add-in for Autodesk Revit to streamline the organization of plan annotations, a task I learned the importance of during my time in architectural practice. Well-organized annotations not only make plans visually appealing but also help convey essential information quickly. The way annotations are arranged reflects echoes that of construction components, providing clarity and highlighting key issues.
In my experience working in MEP coordination, we spent hours manually organizing tags for structural openings from various contractors—HVAC, plumbing, electrical, etc. This repetitive task consumed days on large-scale projects, as each plan needed to be perfectly legible before being passed on for structural analysis.
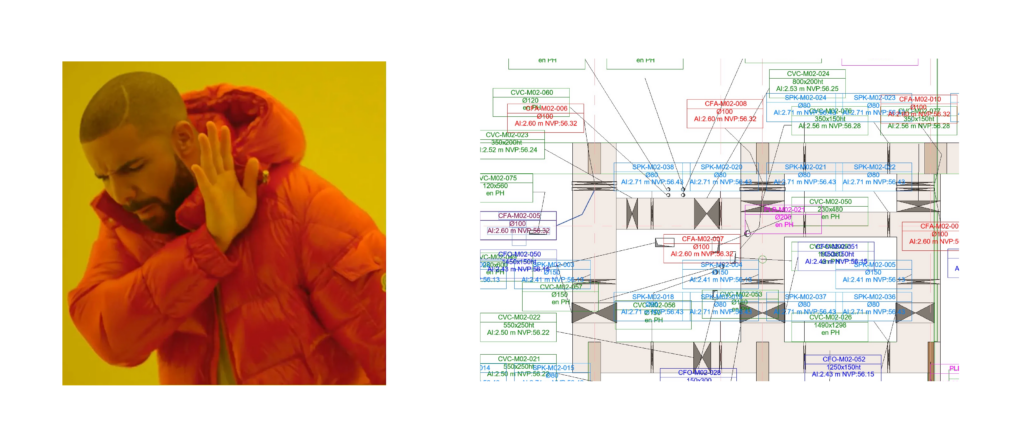
To address this, I initially created a Dynamo script that used rule-based logic to detect and eliminate overlapping tags. While helpful, it struggled with complex plans, failing to recognize patterns like linear or rectangular arrangements of openings.
This led me to explore AI as a more scalable solution. AI offers the potential to better handle larger plans while producing quicker, more accurate results. Moving forward, I’ll document my journey, exploring how AI can enhance Revit workflows, the challenges faced, and the lessons learned.
Let’s get started 😉